Microsoft’s Azure SQL Data Warehouse, the company’s cloud-based database service for big data workloads, is getting yet another speed bump today. A few months ago, the company sped up the service with the general availability of its second-generation compute-optimized tier and today it’s doubling its query performance thanks to the launch of its new instant data movement technology.
Raghu Ramakrishnan, Microsoft’s CTO for Azure Data, tells me that instant data movement is the result of the company’s decades-long investments in database technology. “Given the fact that we’ve been doing data management for decades now, we can marry data storage and management,” he noted and stressed that I/O bandwidth tends to be a major bottleneck for many of the analytics workloads that Microsoft’s customers use SQL Data Warehouse for. In a distributed system like a data warehouse, moving data becomes a problem — one that is typically managed by yet another layer in the system. “In these systems, when you take simple standard operations like joins, if the tables are not already nicely organized by an attribute, you have to sort on one or the other, so you have to move data across the network at a rapid clip, Ramakrishnan said.
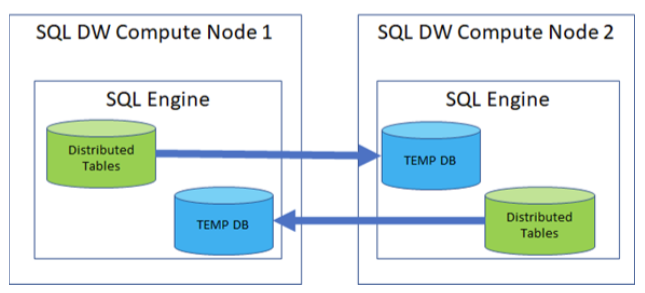
To do away with this bottleneck, Microsoft has now integrated the data movement layer right into the SQL Server engine that powers its data warehousing service. Thanks to this, every SQL Server node can now create intermediary results and move the data as necessary.
Never shy to compare its services to its competitors, Microsoft also notes that Azure SQL Data Warehouse can support up to 128 concurrent queries now, compared to the 50 that Amazon Redshift is currently limited to.
0 coment�rios:
Post a Comment